
DX(=Digital Transformation)は、ビジネスや技術、双方の幅広い観点から理解する必要があります。
本記事では、DXのDigital(技術)領域から、『ビッグデータ』と『データサイエンス』について紹介します。
ビッグデータとデータサイエンス
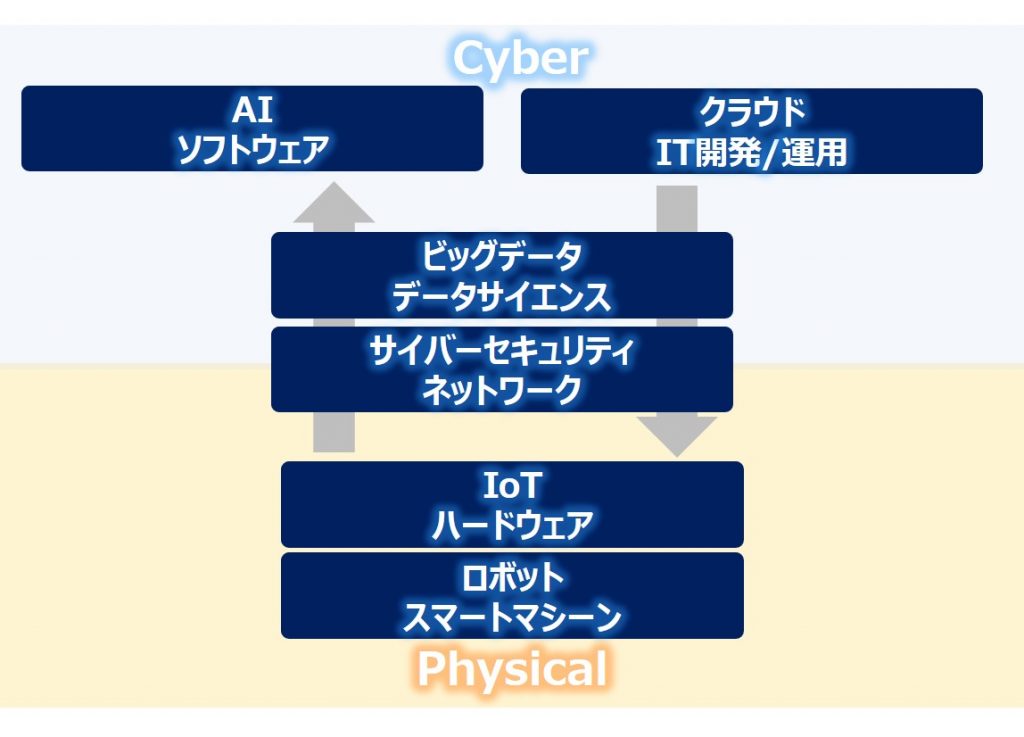
DXの実現は、様々な技術により支えられています。
今回は、そのうち現実世界(Physical World)とデジタル世界(Cyber World)を繋ぐ『ビッグデータ』と『データサイエンス』について、おさえるべきトレンドを紹介します。
ビッグデータ
ビッグデータ
ビッグデータは、「Volume(量)」、「Variety(多様性)」、「Verocity(速度)」の3Vを備えた、「事業に役立つ知見を導出するためのデータ」です。
ビッグデータの種類
ビッグデータの種類には以下を挙げることができます。
| ソーシャルメディアデータ (SNSデータ) | ソーシャルメディアにおいて参加者が書き込むプロフィール、コメント等 |
| マルチメディアデータ | ウェブ上の配信サイト等において提供される音声、動画等 |
| ウェブサイトデータ | ECサイトやブログ等において蓄積される購入履歴、ブログエントリー等 |
| カスタマーデータ | CRMシステムにおいて管理等されるDM等販促データ、会員カードデータ等 |
| オフィスデータ | オフィスのパソコン等において作成等されるオフィス文書、Eメール等 |
| ログデータ | ウェブサーバー等において自動的に生成等されるアクセスログ、エラーログ等 |
| オペレーションデータ | 販売管理等の業務システムにおいて生成等されるPOSデータ、取引明細データ等 |
| センサーデータ (IoTデータ) | GPS、ICカードやRFID等において検知などされる位置、乗車履歴、温度、加速度等 |
ビッグデータ解析
「事業に役立つ知見を導出する」活動をビッグデータ解析といいます。
企業は、以下のような企業関連データの表現・予測・経営力向上目的でビッグデータ解析を行います。
| Webサイトを改善したい | アクセス解析 |
| 顧客や市場を詳しく把握したい | マーケティング分析 |
| 未来を予測したい | 機械学習 |
| 傾向や結論を出したい | データサイエンス |
また、データ解析の技法をビッグデータのような大規模データに適用することで知識を取り出す、ビッグデータ解析に用いる手法を『データマイニング』といいます。
ビッグデータ技術
NoSQL (Not Only SQL)
従来主流であったデータベースはSQL(Structured Query Language)を使う「RDB (リレーショナルデータベース)」でしたが、大容量データを取り扱う際の処理速度が低下するためビッグデータには不向きでした。
この課題に対応すべく、RDB以外のデータベースにより膨大なデータ量に対しても高速な処理を実現する、「NoSQL (Not Only SQL)」が注目されています。
DWH (Data WareHouse)
DWH(Data WareHouse)は、データの倉庫、すなわちデータを保管するデータベースですが、オンプレミスとクラウドの2つの形態で提供されます。
| オンプレミス型 | DWHアプライアンス | DBMS(DataBase Management System)とストレージを含むハードを組み合わせた製品 |
| クラウド型 | DWHサービス | インターネット経由で、統合された時系列データストア機能 |
これらは用途に応じて使い分け、例えばIoTのような現場でのリアルタイム分析(エッジ・アナリティクス)を要する場合はオンプレミスを活用します。
分散処理
大量にデータが流通するビッグデータを高速処理するために「分散処理」の概念が導入されました。
MapReduce
MapReduceは、大量データを分散処理させるためのオープンソースのソフトウェアフレームワークです。
長時間かかる処理を複数のマシンに分散させるフレームワークで、Hadoopの元となったものです。
Hadoop
Hadoopは、ビッグデータのような大規模データの分散処理のために、MapReduceを元に生み出されたオープンソースのソフトウェアフレームワークです。
Apache Spark
Apache Sparkは、Hadoopが苦手とするリアルタイム処理を実現するものとして生み出された、分散処理のためのオープンソースのソフトウェアフレームワークです。
Hadoopはメモリに乗り切る以上のデータ処理、Apache Sparkはリアルタイム高速処理が必要なデータ処理と、共存関係にあります。
データサイエンス
統計解析とデータサイエンス
統計解析(アナリティクス)
統計解析(アナリティクス)は、コンピュータが登場する以前からある、データを収集・探索・分析し、データに含まれるパターンや傾向を明らかにする学問、以下の『記述統計』と『推測統計』からなります。
- 記述統計… 標本データが持つ情報を多面的に明確化することで、データの特性を把握することを目的とした統計
- 推測統計 … 標本データを元に、母集団や、母集団が持つ特徴を推測する統計
データサイエンス
DXの推進と共に爆発的に増加するデータ(ビッグデータ)を有益に扱う学問として、『データサイエンス』が期待されています。
『データサイエンス』は、統計解析などの情報科学を活用しデータを分析、新たな価値を生み出すことに重きを置く学問です。
また、データ・サイエンスに取り組む人を『データサイエンティスト』といいます。
データサイエンスのツール
データサイエンスツール
データサイエンスツールは、ビッグデータと高度な分析技術の組み合わせにより企業が膨大なデータを管理、モデリングプロセスをスピードアップするようデータ分析者(データサイエンティスト)を支援するツールです。
以下の4つが代表的な商用製品です。
- Watson Studio (IBM)
- Cloudera Data Science Workbench (Cloudera)
- Domino Data Science Platform (Domino Data Lab)
- Oracleが買収したDataScience.comのツール
BIツール
BI (Business Intelligence)ツールは、企業に蓄積された大量のデータを、専門知識がないデータ利用者でもデータ分析を可能とし、経営戦略や意思決定、マーケティング分析に役立てられるツールです。
主なBIツールとして以下が挙げられます。
- Tableau
- QlikView
- PowerBI
- Cognos
- SAS
データクレンジングツール
データサイエンスにおいては、分析するデータの品質を高めるため、データレコードの重複・誤記・表記ゆれなどを修正・統一する「データクレンジング」処理が重要です。
そのため、データクレンジングに特化したツールも多く登場しています。
データフレーム操作パッケージ
データサイエンスにおいては、「データフレーム(二次元配置のデータ構造)」操作が重要です。
統計解析・データサイエンス向けプログラミング言語である『R』のデータフレーム操作パッケージである『dplyr』が注目されています。
まとめ
本記事では、DXのDigital(技術)領域から、『ビッグデータ』と『データサイエンス』について紹介しました。
DXの技術領域については、下記書籍が最もよくまとめられていますので、興味を持たれた方は、合わせてお読みすることをオススメします。


コメント