
データサイエンスの領域において、基本中の基本でありながら、どこまでいっても重要となるのが「要約統計量」です。
各指標の特徴を理解することで、データの特性や、複数データ間の違いをおさえることができます。
本記事では、この「要約統計量」について説明します。
「要約統計量」によるデータ特性理解
いわゆる標本データというものは、データをそのまま並べただけではデータの特性理解が困難です。
例として、AとB、2クラスのテストの得点データを以下に示します。
| クラスA | 10 | 20 | 30 | 40 | 40 | 50 | 60 | 70 | 70 | 90 |
| クラスB | 40 | 40 | 40 | 40 | 50 | 50 | 50 | 60 | 60 | 60 |
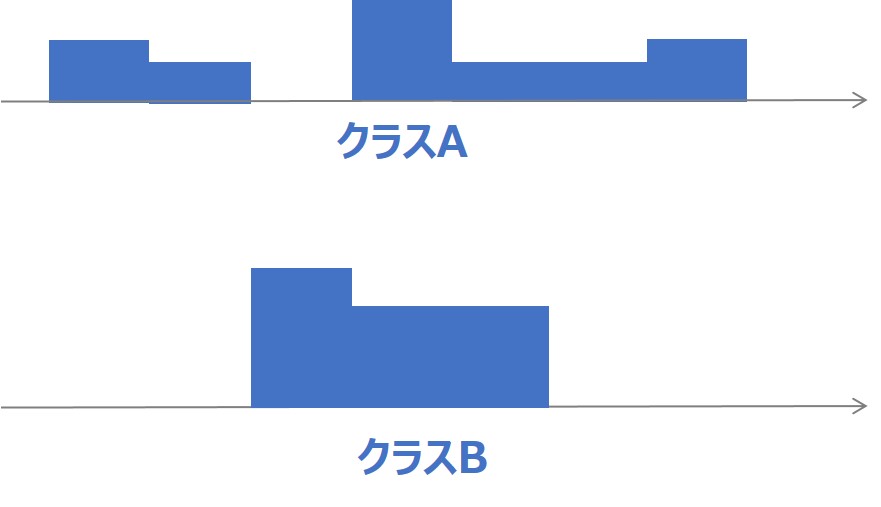
上記のよう、このままでは、「どちらのクラスが優秀か」、「得点にばらつきがあるのか」などの把握が困難であるため、『要約統計量』を求めることで、容易にデータ特性理解を実現します。
上記のテストデータの『要約統計量』は以下のようになります(各指標の説明は後に行います)。
| クラスA | クラスB | ||
| 代表値 | 平均値(AVERAGE) | 51 | 49 |
| 中央値(MEDIAN) | 50 | 50 | |
| 最頻値(MODE) | 50 | 40 | |
| 散布度 | 分散(VAR.S) | 499 | 77 |
| 標準偏差(STDIV.S) | 22 | 9 | |
| 範囲(MAX – MIN) | 60 | 20 | |
分散・標準偏差はそれぞれ「VAR.P」、「STDIV.P」で計算することもできますが、実用であまり意識する必要はありません。
上記の要約統計量により、平均値や中央値といった「代表値」は同等でるものの、分散や標準偏差といった「散布度」に大きな差が見られる、具体的には「クラスBの得点のばらつきがクラスAと比較して大きい」ことが判断できます。
なお、クラスAとBの2つの得点データをヒストグラム(度数分布)で表現すると、下記のようになりますので、上記の仮説が正しいことがわかります。
要約統計量とは
上記のように、データを要約した統計量を『要約統計量』といいます。
要約統計量には、代表値(データを1つの値で代表させたもの)と、散布度(データのばらつきを定量表現したもの)が存在します。
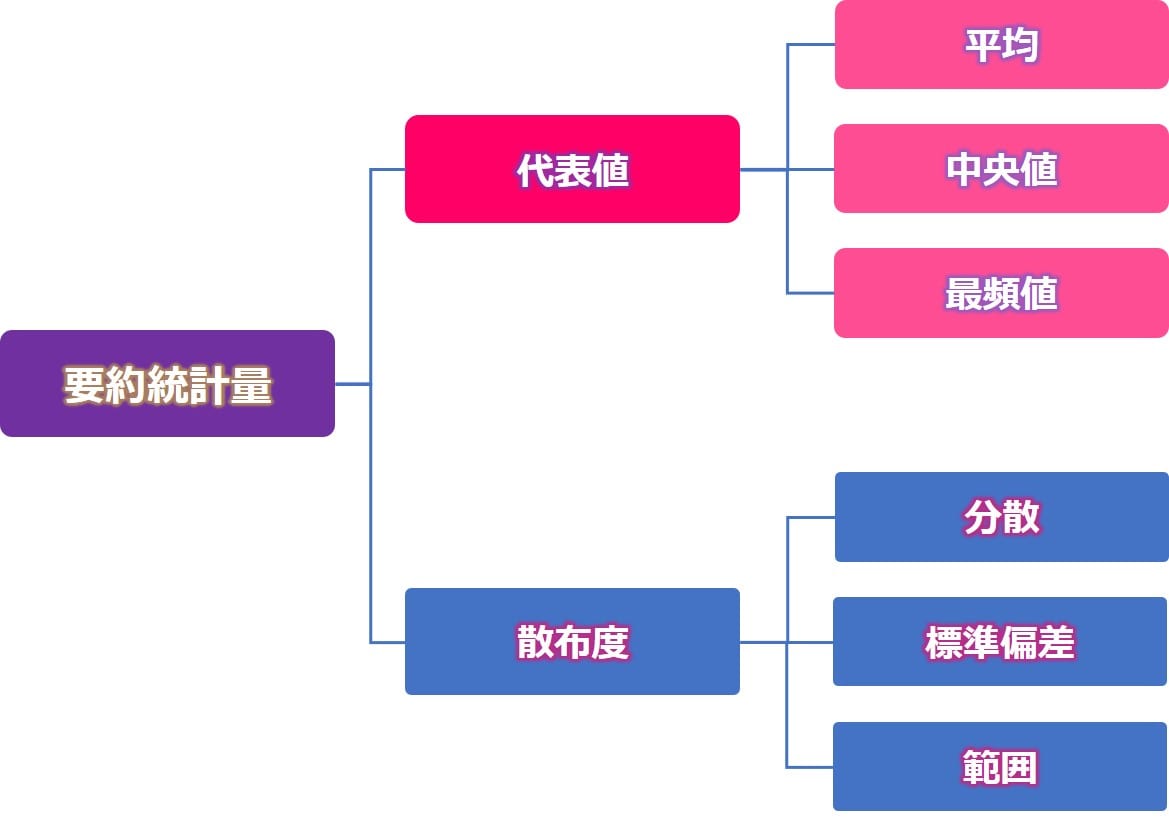
以下に、それぞれの指標を紹介します。
代表値
「代表値」は、データを1つの値で代表させたものです。
平均(AVERAGE)
「平均」は、全てのデータ値の総和を度数で割ったものです。
中央値(MEDIAN)
「中央値」は、データの値を大きさの順に並べた場合に、中央に位置する値です(例えば、11つのデータの場合、6番目の値)。
中央値は、データに外れ値がある場合に用いられることが多いです。
極一部のお金持ちが数億円の資産を所有している(外れ値がある)だけで、簡単に平均値が変わってしまうためです。
そのため、このような場合では、中央値を代表値として用いたほうが適しているといえます。
最頻値(MODE)
「最頻値」は、最も度数が多いデータの値です。
散布度
「散布度」は、データのばらつきを定量表現したものです。
分散(VAR.S)
「分散」は、散布度の代表指標である「標準偏差」を求めるための指標です。
各データの「データの値と平均値の差分の2乗」の合計値を、データ数で割ったものです。
標準偏差(STDIV.S)
散布度で最も用いられるのが「標準偏差」、皆さんご存じであろう『偏差値』にも、標準偏差の概念が使用されています。
「分散」は、上記のように元のデータ単位が2乗されているため、「標準偏差」では、平方根をとることで単位を合わせたものとなります。
範囲(MAX – MIN)
データの最大値と最小値の差で求められる「範囲」も散布度の一つです。
しかし、算出方法の通り、最大と最小のみに着目し、間のばらつきを無視した指標となるため、統計学の領域では、あまり用いられることはありません。
まとめ
統計学の基礎中の基礎であり、とても重要な「要約統計量」について説明しました。
統計学をよりしっかりと理解したい方は、下記の書籍がオススメですので興味があったら一読してはいかがでしょうか。
また、さらに統計に興味を深めた方は、「統計検定」の受験をオススメします。
統計検定の記事を下記にまとめていますので、合わせてお読みください。



コメント